THỐNG KÊ CÓ LỪA AI?
Bài này sẽ tập trung vào một số vấn đề thống kê khi gặp trong việc tìm alpha và cách nhận diện và xử lý nó.

Mở đầu:
Mình rất thích thống kê sau suốt nhiều năm đi làm vì nó là cái cuối cùng mình cảm thấy nó không có fraud khi va chạm, hầu hết các vấn đề mình gặp khi đi làm đều đằng sau nó có 1 câu chuyện gì đó không đúng đắn hoặc có hàm ý riêng (đa phần đều là những người khá cộm cán và rất giỏi). Thống kê từ công cụ dần trở thành là homie lúc nào không hay vì nó có một thứ mình nghĩ đó là nó không nói láo! Điều đó nên có 1 số bài viết (có thể câu view) gần đây có nội dung như “sự lừa dối của xxx, jav,…” thì mình thấy không hứng thú lắm vì thực tế đó chỉ là một số lệch lạc về thống kê do người đọc, người phân tích (đa số) nhầm lẫn. Số liệu có thể nói láo, con người có thể nói láo, tổ chức có thể nói láo,… nhưng thống kê không bao giờ nói láo!
Bài này thì vẫn là về thị trường và backtest để tìm alpha, tuy nhiên thì mình sẽ tập trung vào vấn đề backtest sâu hơn để bóc tách ra những nhầm lẫn hay gặp (có support của các chương trình học thuật và 1 số kiểm chứng tại Việt Nam) để phân biệt rõ.
Tóm tắt kết quả:
Bằng các sử dụng quan sát về SR hội tụ và correlation giữa các strategies đã giúp chúng ta phát hiện các vấn đề cần lưu ý khi backtest. Backtest/thống kê không “lừa dối” chúng ta mà chỉ có chúng ta “stupid” (do các bias) để nhìn nhận sai lầm và đánh giá backtest 1 cách cảm tính để trade.
I. QUY TRÌNH BACKTEST VÀ MÔ PHỎNG
Lợi nhuận có thể xuất phát từ việc quan sát của mỗi cá nhân hoặc đọc nghiên cứu hoặc là '“rùa” (may mắn). Tuy nhiên, alpha thì cần phải có sự rõ ràng nhất định (chẳng hạn là có bằng chứng trong 1 khoảng thời gian nào đó trong quá khứ), alpha cũng không phải là “chén thánh” và nó sẽ bị hao mòn (decay) qua thời gian cho 1 yếu tố, thực sự là đ** có “chén thánh” nào cả (hoặc có thể do mình chưa “nhập cõi” chăng) kể cả fundamental mà nhiều người cuồng tín, cái tốt nhất là có 1 rules set rõ ràng khi phân tích và execute để giảm yếu tố phi lý trí.
Khi có 1 ý tưởng về 1 alpha tiềm năng, quy trình để kiểm chứng nó sẽ như sau:
Tiền xử lý dữ liệu (preprocessing data): Bước này không phải là EDA, nó là bộ lọc dữ liệu bẩn. Dữ liệu thực tế sẽ gặp rất nhiều vấn đề như OHLCV không chuẩn, dividend split, timestamp index, đơn vị, thiếu dữ liệu,… —> Tất cả cái này phải được xử lý để nó sạch, cân xứng.
Biến dữ liệu thô thành các đặc trưng (Feature engineering): tại bước này thì các yếu tố có thể được tạo alpha có thể được vẽ lên để quan sát sơ bộ (quan sát bằng mắt) để nhận diện quy luật và kiểm chứng (signal analysis). Bước này trong CMT gọi là signal testing và nó là cái quan trọng nhất. Một số nghiên cứu về quant của “giáo chủ” Lopez De Prado cũng có nói về causal factor investing khi phân tích (thực tế nó work rất tốt).
Modeling: 2 phần này sẽ là một bước, modeling sẽ tạo các strategies theo dạng rules-based (nếu người dùng đã có quy tắc rõ ràng) hoặc dùng các model để nó tự fit và predict. Ưu điểm lớn nhất của rules-based đó là nó nhanh và nó không cần quá nhiều data. Đoạn này quan trọng nhất là tạo skeleton để có thể linh hoạt giữa các rules-based strategies và ML strategies để khi cần có thể kết hợp cả 2.
Backtesting: backtesting để kiểm chứng việc hoạt động của strategies trong quá khứ và quan trọng là nó cần phải fitting in sample (IS) để training trong tệp dữ liệu quá khứ và forecast OOS (forecast cho dữ liệu mới). Vậy vấn đề là nếu chỉ có 1 tệp dữ liệu thì phần OOS đa phần sẽ nghĩ là chia nó làm 2 đoạn và làm, cao cấp hơn thì sẽ là walkforward testing (WF) hoặc là như Lopez có chỉ là Combinatorial Purged K-Fold (CPKF).
Sau khi backtest và có được strategies tốt nhất —> deploy lên hệ thống để chạy live trading.
II. BACKTEST VÀ NHẦM LẪN THÔNG DỤNG
Nếu backtest bằng các phương pháp tiên tiến hơn như CPKF hoặc WF thì vẫn chưa đủ và nó có những hạn chế như sau:
CPKF sẽ có tác dụng chỉ muốn xem độ bền của strategies, không phải là thước đo trading chuẩn tắc hoàn toàn, nó xác định bằng cách bootstrap từ dữ liệu quá khứ và nó không trả lời được các vấn đề vì các tệp test data thường rất bé. Thậm chí, nếu data đủ lớn (rất khó lấy ở Việt Nam) thì tính toán cũng là một vấn đề vì CPKF thực tế chạy rất chậm.
Walkforward testing rất có tác dụng nếu nói về mức độ thực tế vì nó có thể chọn 1 khung thời gian cố định để fit dữ liệu trong quá khứ vào đó (tương tự như 1 analyst lấy số liệu của 1 kỳ trước để so sánh với kỳ hiện tại chẳng hạn) và kết quả của nó là động (rolling) có thể tổng hợp các mảnh ghép dữ liệu lại để nhìn sự liên tục của nó qua thời gian. Chẳng hạn như Sharpe ratios của 1 chiến lược hình dưới qua thời gian:
Mô tả sơ về chiến lược:
Dữ liệu chạy: hơn 1600 cổ phiếu và được lọc ra nhóm có thanh khoản cao nhất (x.xx%) + có signal để trade. Dữ liệu sẽ được chạy từ 2020 - nay (khoảng hơn 1500 ngày) và được tự động filter mỗi ngày giao dịch trong khoảng thời gian này để tìm signal. Có nghĩa là nếu mỗi lần cái universe này nó thay đổi thì nó sẽ chọn 50 - 60 cp để lọc ra các signal (thường sẽ có từ 4-5 mã có signals) thì tổng số sự lựa chọn có thể là 1500*4 ~ 6.000 sự lựa chọn cho tổng số mẫu lựa chọn nếu không xét trường hợp là các mẫu này trùng nhau.
Khi trade sẽ được tự động cân đối tỷ trọng danh mục (sử dụng HRP/Inverse Volatility/MeanRisk tùy vào model nào outperform mỗi lần rebalancing) + tuân thủ constraint của thị trường (T+2.5), các chi phí giao dịch (transaction cost) sẽ được mô phỏng bằng slippage ngẫu nhiên (tất nhiên vẫn trong range của +/-7% cho HSX và HNX hoặc +/- 15% của UPCOM) và fixed cost cho thuế và phí giao dịch.
Đây là TA chiến lược thuần túy với 2 đường MA cơ bản, rules sẽ gồm momentum và meanreversion. Momentum sẽ là giá cắt lên 2 đường MA có volume confirm —> MM buy signal. Meanreversion là giá chạm fast ma trong khi vẫn trên slow ma và có volume confirm, doji candle confirm —> MR buy signal.
Nguyên tắc fit là fit các fast_ma window và slow_ma window sao tổ hợp này sinh ra signal có Sharpe cao nhất trong 1 span cụ thể (chẳng hạn 252 ngày). Các window để fit sẽ từ 10 - 50 cho fast ma và 80 - 150 cho slow_ma với step là 10, vậy là sẽ có khoảng 35 tổ hợp giữa các window để fit cho các data và kết hợp với 6.000 sự lựa chọn ở trên thì sẽ là những sự lựa chọn tối ưu được chọn ra từ 35*1500*50 ~ 2.625.000 sự lựa chọn.
Các tickers cũng sẽ được dùng portfolio weights để cân đối rủi ro của nó, điều này cũng là 1 bước sàng lọc overfitting cho strategies và optimizer cũng sẽ tự động lựa chọn cái tối ưu nhất.
Đến đây thì mọi thứ có vẻ khá ngon khi backtest gần như mô phỏng 1 trade trên đời thực hoàn toàn với tất cả các điều kiện cần thiết để tối thiểu hóa rủi ro và chống overfitting. Tuy nhiên, thực sự nó có ngon không? Kết quả như sau:
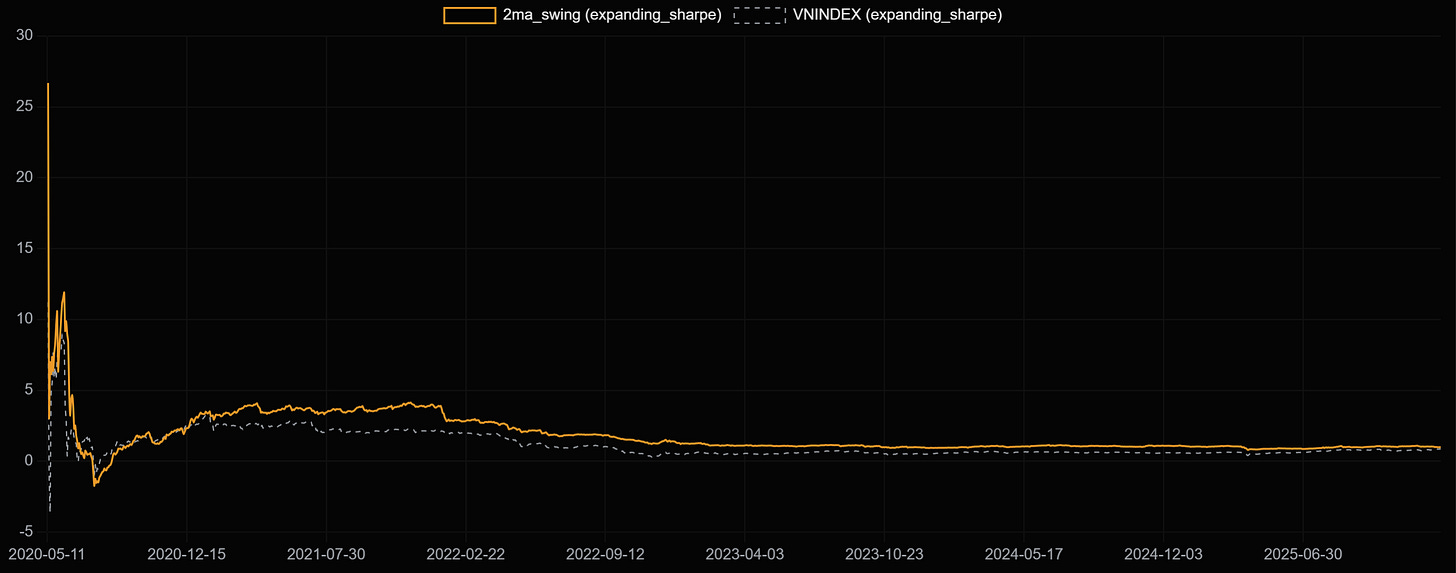
Nếu chỉ chọn 1 mốc thời gian là 2022 để đánh giá thì rõ ràng Sharpe của nó cao hơn nhiều so với VNINDEX, thậm chí hiệu suất của nó là còn rất tốt nếu nhìn hiệu quả OOS như sau:
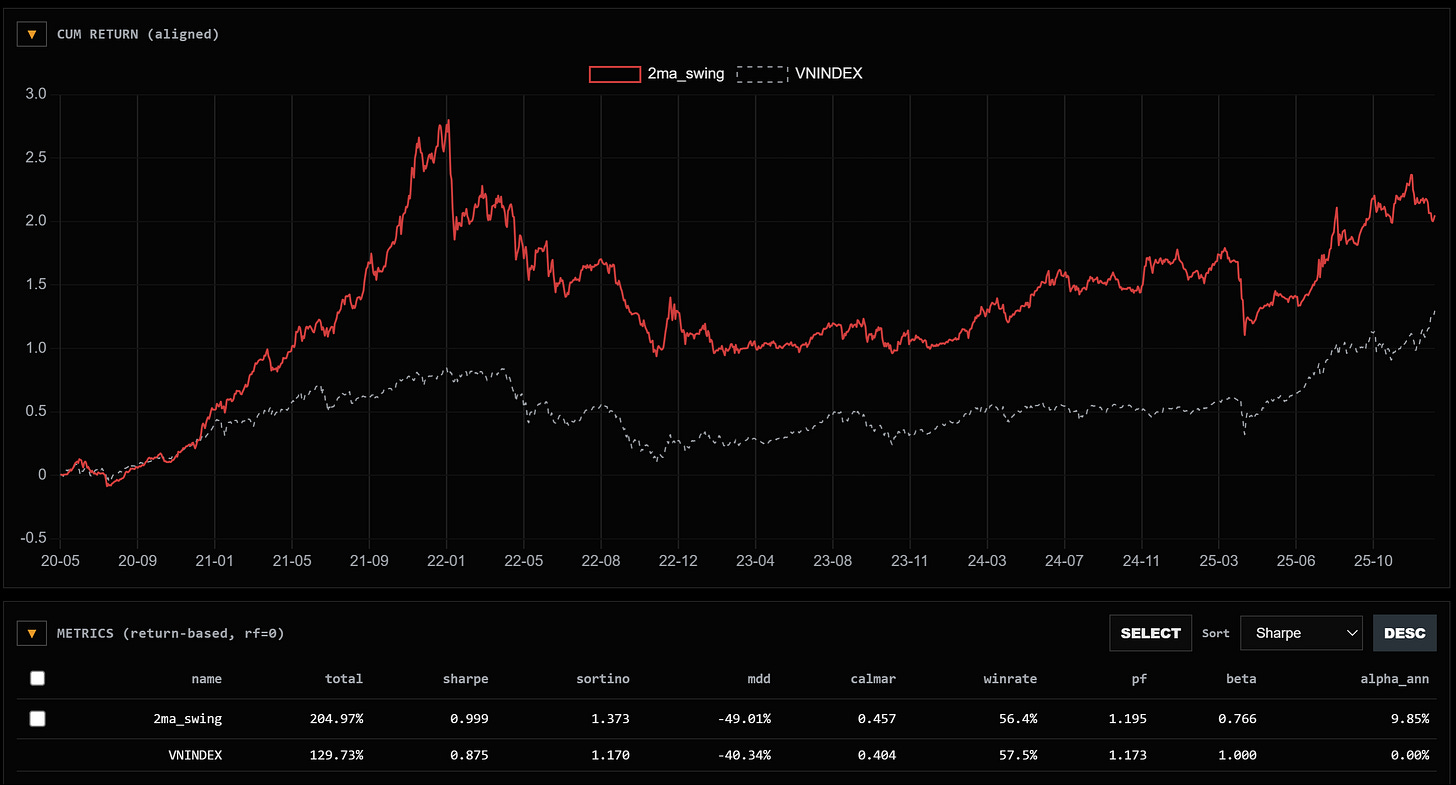
Sharpe ratio (SR) của chiến lược này là 0.999 và vượt trội hoàn toàn so với VNINDEX cho tới thời điểm hiện tại. Nếu một cách bồng bột thì mình sẽ kết luận nó ngon và đem chạy live (sau đó cháy tài khoản thì quay lại bảo sự lừa dối của backtest =)))) —> Đây là một lệch lạc phổ biến và dễ mắc phải.
Thực tế nếu nhìn đường SR qua thời gian có thể thấy nó đang dần hội tụ về VNINDEX Sharpe ratio, có nghĩa chỉ bằng quan sát thôi cũng thấy SR này chưa đủ độ tin cậy qua thời gian!
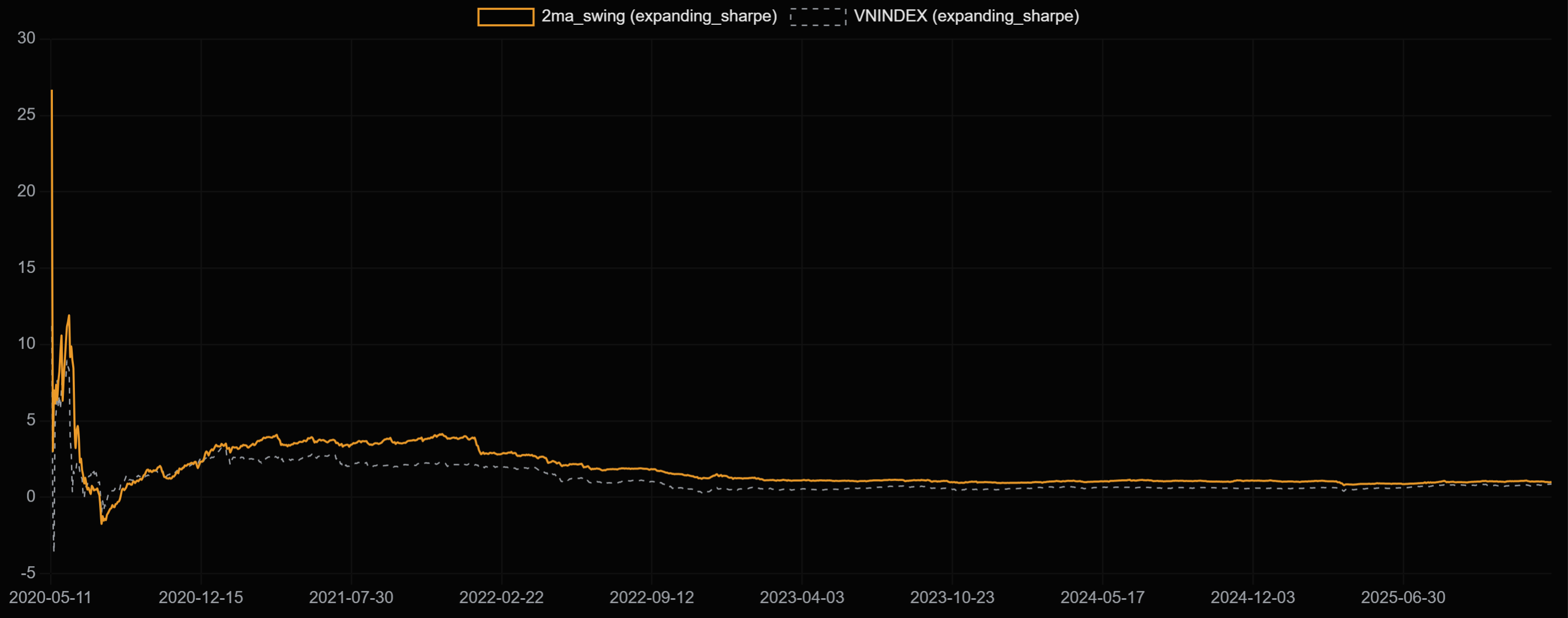
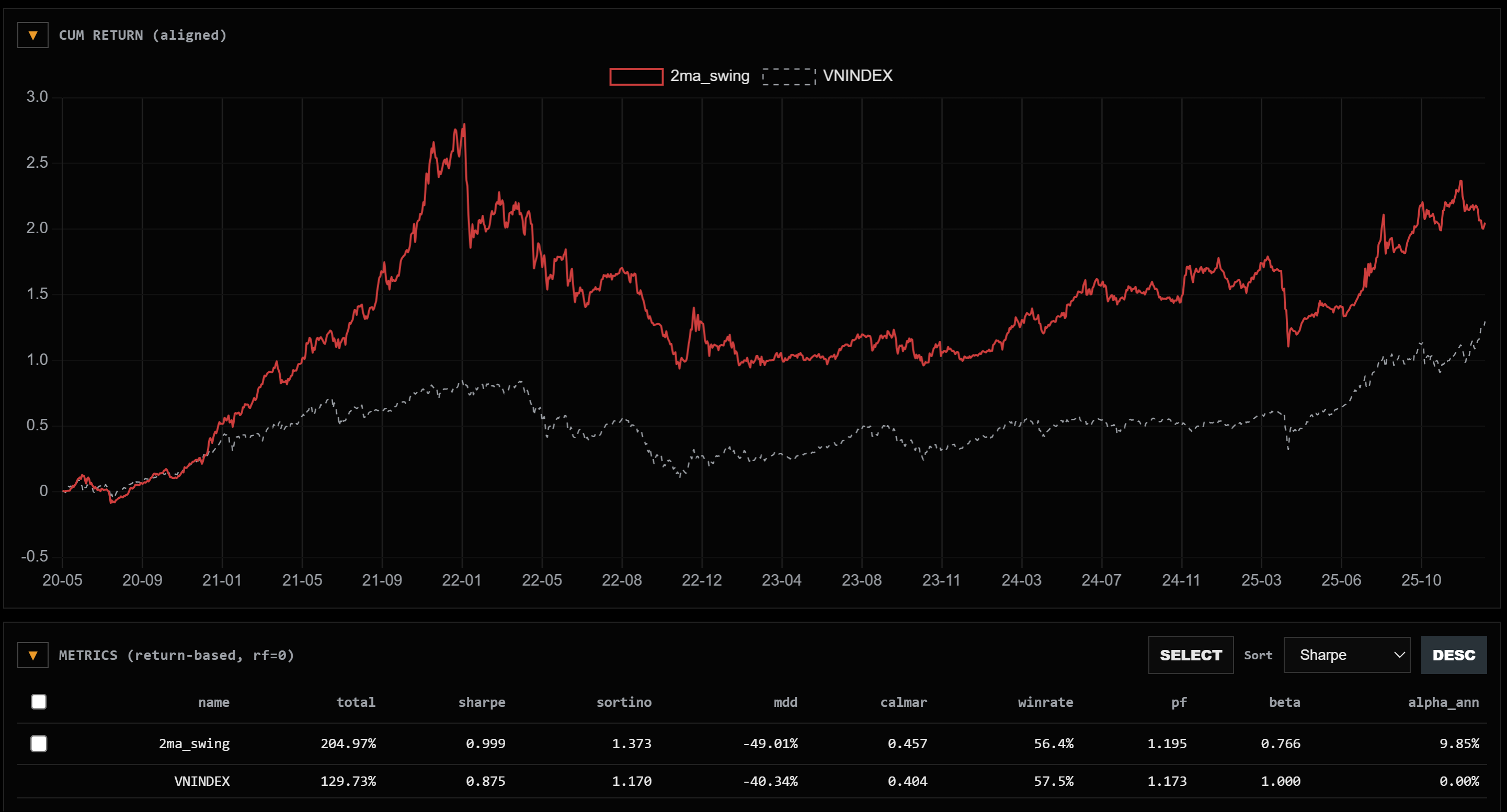
Vậy giả sử nếu chúng ta tiếp tục kiểm chứng qua các universe khác thì sao? Nếu 1 strategy ổn định thì nó phải chạy tốt qua hầu hết các tickers phải không? Nghe rất hợp lý, vậy để kiểm chứng nó thì giả sử cũng là strategy ma_swing ở trên nhưng chạy với các bộ lọc khác nhau thì kết quả sẽ như sau:
Equity curve của các strategies đều có vẻ là ngon so với index
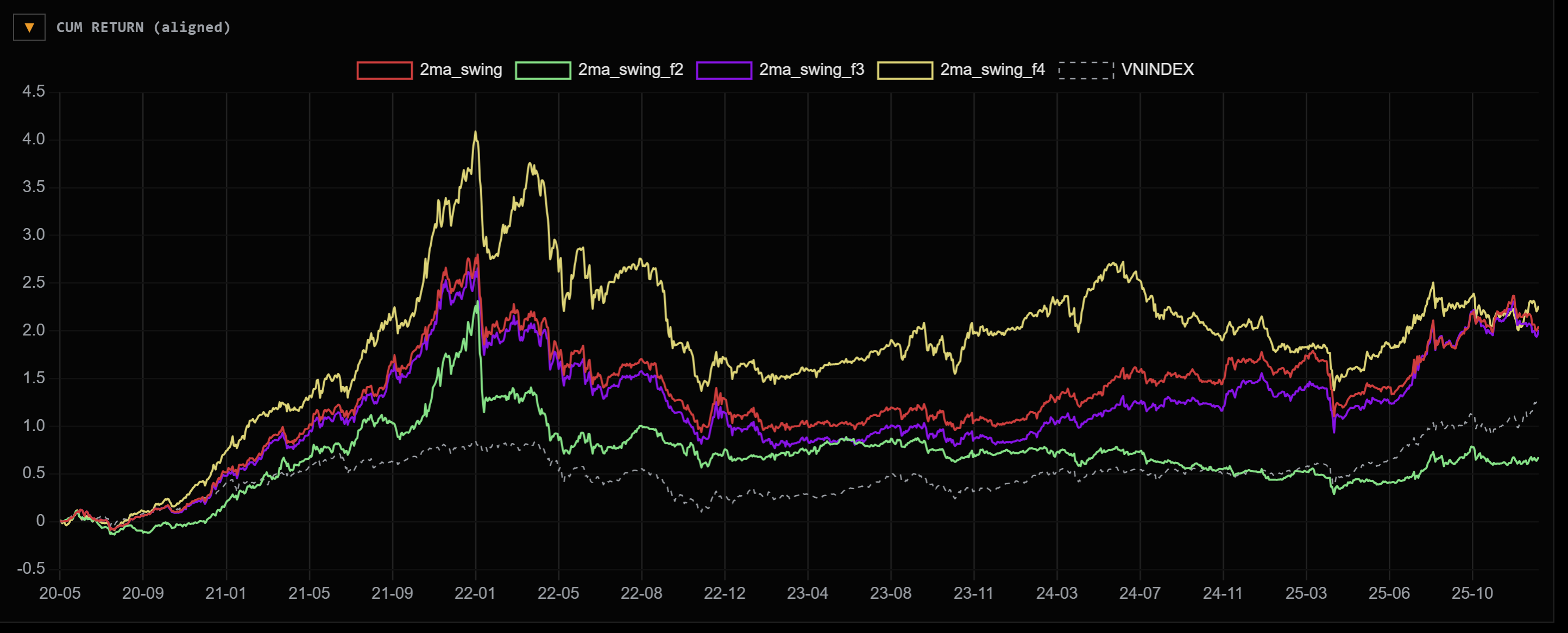
Hiệu suất cũng có vẻ khá ngon, hầu như cái nào cũng tăng 200% so với thời điểm 2020, sharpe, sortino đều vượt trội hoàn toàn index là VNINDEX.
Tuy nhiên thì correlation của các strategies khá cao:
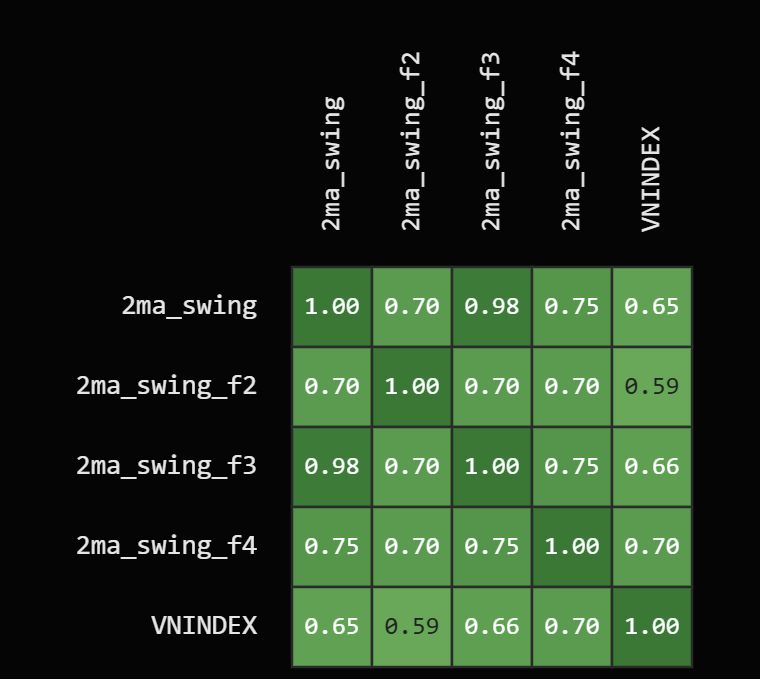
Nếu tính trung bình của tất cả các các correlation giữa các strategies trong correlation matrix này thì kết quả sẽ ~ 0.81 là rất cao và thống kê gọi đây là có hiện tượng đa cộng tuyến (multicolinearity), điều này có nghĩa là các strategies này dù có các filter khác như nhưng không khác biệt đáng kể vì bị đa cộng tuyến.
Điều này là đơn giản là vì các vấn đề như sau:
Latent factors của toàn bộ thị trường: các cổ phiếu được lựa chọn vẫn là tài sản là cổ phiếu —> có các yếu tố rủi ro ẩn liên quan đến nó và đặc thù của riêng nó.
Selection bias: mặc dù chúng ta nghĩ rằng bộ lọc có thể khử được các yếu tố liên quan đến nhau, các pattern của cp trong quá khứ là không thay đổi, điều khác biệt là chúng ta chỉ cắt (crop) 1 khung thời gian nào đó trong các nhóm cổ phiếu để ghép lại với nhau. Cụ thể là là nếu có 1600 cổ phiếu thì chỉ có chính xác 1600 paths (con đường) trong quá khứ của mỗi cổ phiếu đã đi qua do đó các kết quả của nó là hữu hạn và rất giới hạn rất nhỏ.
Nếu không nhìn nhận đến các vấn đề này thì sẽ rất dễ bị rớt vào bẫy gọi là multiple-testing bias hoặc còn gọi là Type I error trong thống kê (type II error là bỏ sót strategies vì bị đánh giá sai, cái này thì khó thấy hơn nên có dịp mình sẽ nói sau). Cái này là sao? Cái này nôm na là việc càng test nhiều lần cho 1 cùng bộ dữ liệu thì xác suất chúng ta bác bỏ giả thuyết H0 là strategy chúng ta tìm được là alpha càng cao. Tuy nhiên, đây không phải là alpha mà là chúng ta đã bị ảo giác vì sự lặp đi lặp lại trên 1 tệp dữ liệu. Một số người gọi đây là survivorship bias, theo tôi nghĩ thì nó không phải là survivorship bias hoàn toàn mà nên là multiple-testing bias (ngộ nhận do kiểm chứng nhiều) vì nó có tính tổng quát hơn. Việc ngộ nhận này sẽ dẫn đến việc là chúng ta deploy các strategies không hiệu quả hoặc bị overfitting do chúng ta test quá nhiều.
Vậy, bằng các sử dụng quan sát về SR hội tụ và correlation giữa các strategies đã giúp chúng ta phát hiện các vấn đề cần lưu ý khi backtest. Backtest/thống kê không “lừa dối” chúng ta mà chỉ có chúng ta “stupid” (do các bias) để nhìn nhận sai lầm và đánh giá backtest 1 cách cảm tính để trade.
Vậy làm sao để xác định được alpha nếu chúng ta đã test dọc (chiều sâu của chiến lược khi chống các vấn đề overfitting) và test ngang (qua nhiều bộ lọc khác nhau) để có thể deploy nó được?
Việc này mình sẽ để các bạn tự tìm vì đó sẽ là alpha của các bạn.
Cảm ơn và trân trọng!
Omg tuyệt vời
👍👍 góc nhìn thú vị